
By Natan Yellin, Robusta.dev co-founder
On Kubernetes, the best practice is to set memory limit=request. This surprises many people, especially because we recommend not setting Kubernetes CPU limits altogether! Why is memory different than CPU?
We will explain with an analogy between pizza parties and Kubernetes clusters. As you will see, when guests are allowed to eat more pizza than they ordered (i.e. when memory limit > memory request) then chaos ensues.

Kubernetes memory limit and requests, in form of an analogy about pizza
I owe a huge thank you to Chris Love, André Bauer, Hilliary Lipsig, Aviv Dozorets,Adam Hamsik, Michal Hruby, Nuno Adrego, and slaamp for reviewing this post in advance, finding inaccuracies, and suggesting improvements!
The danger of setting memory limits higher than requests
Imagine a pizza party where each guest orders two slices and is allowed to eat up to four slices. When ordering pizza from the shop, you assume 2 slices per guest, but at partytime (runtime) you limit consumption with 4 slices per guest. In Kubernetes terms, Pizza Request = 2 and Pizza Limit = 4. As we will show, setting limit > request is asking for trouble.
The pizza party begins! Each table has two slices for each guest sitting there. The pizza pie is smack in the middle of the table and everyone can take from it. In the middle of the party, you casually reach to take a slice but it isn't there! Someone else ate your pizza!
A huge bouncer appears from nowhere and shouts "OUT OF PIZZA KILLER (OOP KILL)". He delivers a powerful side-kick to one of the guests, knocking them to the floor.

A Kubernetes Out of Memory Kill (OOM Kill) in our pizza analogy
The bouncer collects leftover pizza scraps from the fallen guest. He hands them out to other guests at the table to satisfy their hunger. Finally, the bouncer apologizes to the ejected guest and seats them at another table with more pizza.
This is what happens** when there is an Out of Memory Kill on Kubernetes (aka an OOM Kill). OOM Kills occur when pods (technically containers) try to access memory that isn't available. Either another pod is using your memory or you requested too little memory to begin with.
When you set a memory limit higher than your request, you are allowing overutilization of your Kubernetes nodes. You are letting pods use more memory than they requested. You are eating four slices of pizza when you ordered two, and there is a price to pay. The Out Of Pizza Killer is coming for you.
** As pointed out on reddit, the analogy isn't perfect. What really happens with an OOM Kill is that the bouncer forces the guest to eject all pizza already eaten, and that pizza too gets handed out to other guests.
Avoiding Kubernetes OOM Kills
Life would be far less violent if guests were only allowed to eat pizza they ordered. (In technical terms, if Pizza Limits were equal to Pizza Requests.)
Guests would still be able to run out of pizza if they ordered too few slices. (i.e. set a memory request too low.) But it would only have an impact on the guest who ate more than they ordered, not on other well behaved guests at the party. Furthermore, the error would occur earlier and more reliably at the moment that a guest consumed too much memory, not at a later moment when pizza ran out for the whole table.
This is why you should always set Kubernetes memory limits equal to memory requests.
The difference between memory limits and CPU limits on Kubernetes
Regular readers of this blog know that we recommend a different approach when it comes to CPU limits. Why is that so?
CPU is fundamentally different than memory. CPU is a compressible resource and memory is not. In simpler terms, you can give someone spare CPU in one moment when it's free, but that does not obligate you to continue giving them CPU in the next moment when another pod needs it. There is no downside to giving away idle CPU, because it's easy and non-violent to reclaim it.
Here is how I once explained it on LinkedIn.
(Follow me on LinkedIn for Kubernetes resources and tips.)
Why is memory different than CPU on Kubernetes? Because memory is a non-compressible resource. Once you give a pod memory, you can only take it away by killing the pod. This is the cause of OOM Kills.
Best Practices for Kubernetes Limits and Requests
To paraphrase Tim Hockin, one of the Kubernetes maintainers at Google, the best practice for Kubernetes resource limits is to set memory limit=request, and never set CPU limits to avoid Kubernetes CPU throttling.
This is why I always advise:
1) Always set memory limit == request
2) Never set CPU limit
(for locally adjusted values of "always" and "never")— Tim Hockin (thockin.yaml) (@thockin)
In even simpler, terms do this:
---
apiVersion: v1
kind: Pod
metadata:
name: proper-resource-configuration
spec:
containers:
- name: app
image: this.part-isnt.interesting/robustadev:keepreading
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "64Mi" # the memory limit equals the above request!
# no cpu limit! this is excluded on purposeEdge cases to be aware of
While researching this post, I reached out on twitter to get feedback.
Attention Kubernetes pros!
If you've dealt with memory requests/limit policies on Kubernetes and/or OOM Kills at scale, please let me know!
I'm publishing a post on memory requests/limits soon and want feedback prior to publishing.— Natan Yellin (@aantn)
Here are some interesting nuances that came up.
Unintuitive page-cache behaviour can lead to unecessary OOMs
Adam Hamsik pointed out this open GitHub issue related to OOMKills and the Linux page cache. He recommended running without limits and relying on node memory pressure and pod evictions to bypass the issue.
We plan on researching this more, so stay tuned! Details to follow on our LinkedIn and Twitter.
Due to Kubernetes affinity rules, you can have pending pods despite adequate resources in the cluster
Hilliary Lipsig told me of complex errors she encountered due to affinity rules, pod priorities, and more.
In pizza terms, if you're waiting for a pepperoni slice then you can go hungry even when there are regular slices. What's more, pod priorities and evictions mean that you can be eating a slice when someone else comes from nowhere and grabs it off your plate.
When performance really matters, consider CPU pinning or giving pods dedicated nodes
Aviv Dozorets emphasized that this post has good advice for most companies, but there are cases that justify additional performance tuning. Anecdotally, he reported seeing a 20% improvement when giving data and IO heavy services like Kafka and Trino their own Kubernetes nodes with no neighboring pods.
Nuno Adrego reported similar performance improvements when adding CPU pinning. Without it, pods were jumping between different CPUs on the same node and there was a major performance degradation. To implement it, he added a dedicated EKS node group and added the kubelet flag --cpu-manager-policy=static.
On the Robusta.dev side, we haven't looked at enough cases up close to provide an in-depth analysis. But it does make sense. Isolation between different pods on the same node is never 100% complete. For example, CPU caches are a shared resource and one pod can impact them for others.
Most companies should start with the recommendations earlier in this post, consider CPU pinning when necessary, and move to dedicated nodes if even that isn't sufficient.
Symptoms of OOMKilled Kubernetes Pods
How do you know if you're experiencing OOMKills on Kubernetes anyway? Here are the obvious signs:
- Containers and processes with Error code 137
- Running kubectl get pods and seeing OOMKilled in the status column
- Running kubectl describe pod and seeing a Command terminated with exit code 137 message
- Prometheus alerts like HostOomKillDetected andKubernetesContainerOomKiller (these alerts are often copy-pasted from popular alert collections like Awesome Prometheus Alerts)
- Slack notifications about OOM Killed pods with Robusta's Prometheus-based Kubernetes monitoring 😊
Here is a screenshot of an OOMKill error in Slack. In line with the Robusta philosophy, it contains not just the error but also context.
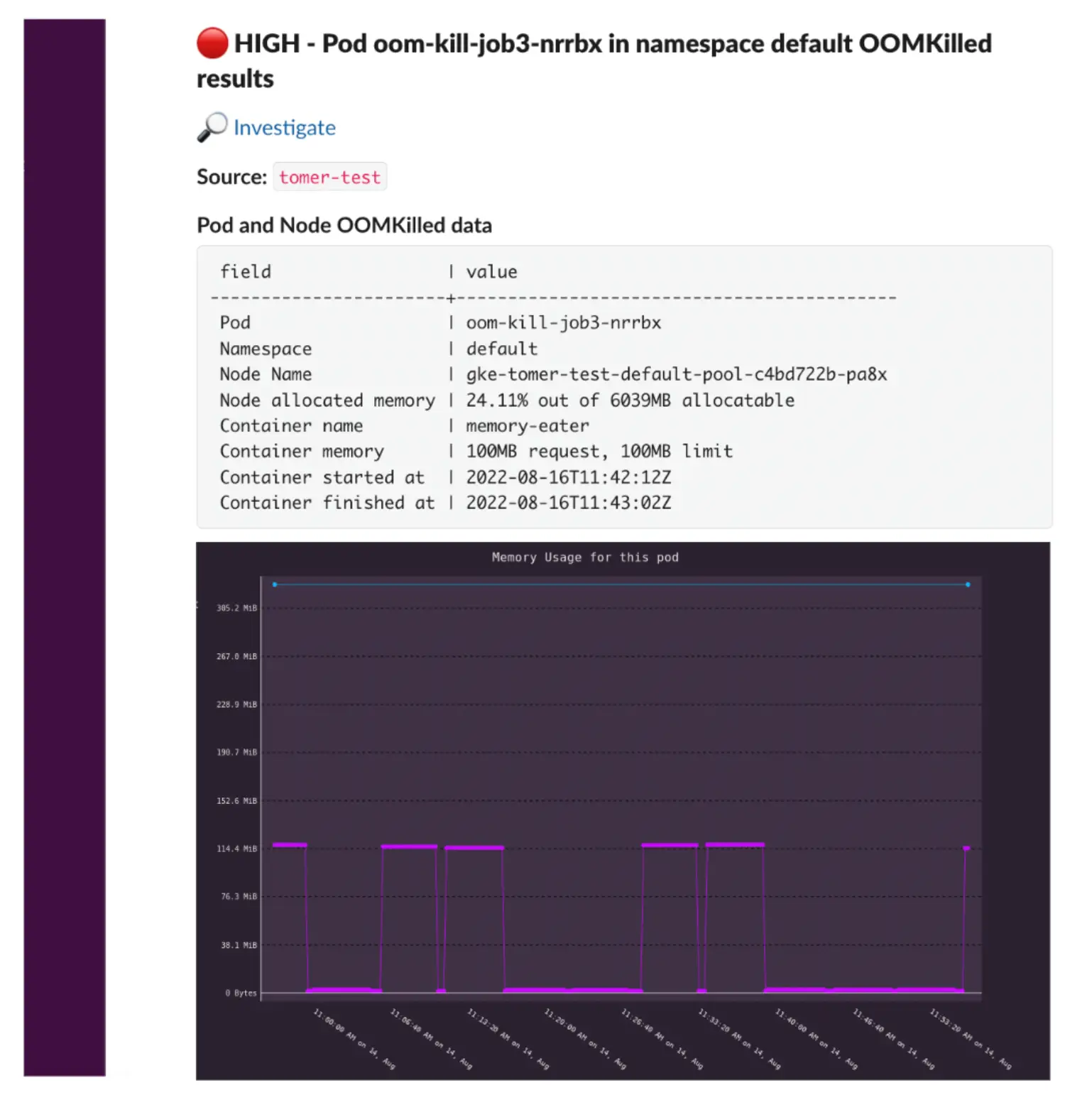
How can you identfy OOM Kills when you're not monitoring them directly? The symptoms will show up elsewhere. For example, pods might suddenly drop connections or crash without notice. When in doubt, look for exit code 137 in the kubectl describe pod output. If a pod exited with code 137, it's an OOMKill for sure!
For now, I'm ordering another slice of pizza.
If you enjoyed this post, tell Natan Yellin on LinkedIn what Kubernetes or SRE topic he should cover next!

Natan Yellin, CEO — Natan has been writing software for over 15 years. He regularly posts about all things Kubernetes on LinkedIn.